On Sparsity in Overparametrised Shallow ReLU Networks
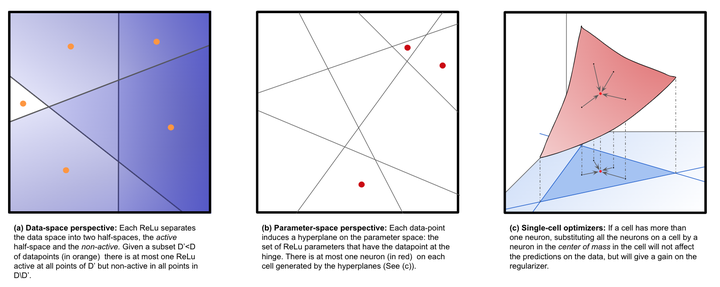 Figure from the paper
Figure from the paper
Abstract
The analysis of neural network training beyond their linearization regime remains an outstanding open question, even in the simplest setup of a single hidden-layer. The limit of infinitely wide networks provides an appealing route forward through the mean-field perspective, but a key challenge is to bring learning guarantees back to the finite-neuron setting, where practical algorithms operate. Towards closing this gap, and focusing on shallow neural networks, in this work we study the ability of different regularisation strategies to capture solutions requiring only a finite amount of neurons, even on the infinitely wide regime. Specifically, we consider (i) a form of implicit regularisation obtained by injecting noise into training targets [Blanc et al.19], and (ii) the variation-norm regularisation [Bach17], compatible with the mean-field scaling. Under mild assumptions on the activation function (satisfied for instance with ReLUs), we establish that both schemes are minimised by functions having only a finite number of neurons, irrespective of the amount of overparametrisation. We study the consequences of such property and describe the settings where one form of regularisation is favorable over the other.